Преобразование текста с помощью регулярных выражений
(или о том, как сделать HTML от MS Word меньше)
Автор: Вадим К
Задача
Я пишу эти статьи в MS Word по той причине, что он (Word) проверяет орфографию и грамматику. Но у него есть один существенный недостаток. Статьи в Интернет публикуются в формате HTML и, хотя MS Word и умеет конвертировать, но делает это отвратительно. Страничка, которая могла бы занимать 3-4 килобайта, имеет вес 20-30. Самое обидное, что всё можно вычистить "ручками", а внешний вид страницы и не изменится.
Чистить текст будем с помощью давно известного метода – регулярных выражений.
Инструментарий
Для того, что бы продолжить работу нам нужно:
- Delphi 7, 2005, 2006, 2007 версии. На младших версиях должно работать, но не гарантирую;
- Скачать библиотеку для регулярных выражений с сайта http://www.regexpstudio.com/RU/TRegExpr/TRegExpr.html. Если точнее, то http://www.regexpstudio.com/Downloads/regexpr_RU.zip и загрузить (это опционально) утилиту для тестирования регулярных выражений http://www.regexpstudio.com/RU/RegExpStudio.html. Всё это также можно взять в архиве к статье.
- Ну и напиток по вкусу :-)
Написание кода
Рабочий класс
Запускаем Delphi и сразу добавляем ещё один юнит (File –> New -> Unit). Сохраняем проект. "Unit2" я сохраняю под именем "ClassTextTransf.pas". "Unit1" как "Main.pas". А сам проект как "HTMLClean.dpr". Теперь из архива извлечем файл "Source\ RegExpr.pas" и скопируем его в папку к нашему проекту.
Возвращаемся к файлу ClassTextTransf. После строки interface подключаем нужные нам файлы – uses SysUtils, Classes, RegExpr;
Со следующей строки начинаем писать заготовку для нашего класса.
type TTextTransf = class private FText:string; FFileName:string; public constructor Create(fileName:string); destructor Destroy; override; procedure Load; procedure Save; procedure Erase(Expr: string); end;
Теперь нажимаем Ctrl+Shift+C и Delphi допишет заготовки для кода.
Некоторые комментарии. FText – переменная, которая хранит собственно сам текст. Load и Save загружает текст из файла и соответственно сохраняет. Имя файла указывается в конструкторе. Рабочий метод у нас Erase. Он получает строку - регулярное выражение, чтобы знать, что заменять на пустую строку, мы ведь удаляем "лишний текст". Его реализацию мы и рассмотрим. Все остальные методы просты и их реализацию можно подсмотреть в прилагаемом архиве.
procedure TTextTransf.Erase(Expr: string); var r:TRegExpr; begin r:=TRegExpr.Create; try r.Expression := Expr; FText := r.Replace(FText,'',false); finally r.free; end; end;
Рассмотрим этот код подробнее. В начале мы создаём экземпляр класса (т.е. объект), который умеет обрабатывать регулярные выражения. Дальше передаём само регулярное выражение и вызываем функцию Replace. Её параметры следующие: первый – строка, в которой мы будем удалять текст, второй – на какой текст будем заменять. Так как мы удаляем, то у нас это пустая строка. Третий параметр пока оставляем False. Он расширяет функциональность и нам пока не нужен. Далее записываем полученный текст назад в нашу переменную. Как составлять регулярные выражения – разберёмся позже.
Интерфейс
Теперь пишем интерфейсный код – юнит main.pas. Для начала набросаем компоненты. У меня получилось так:
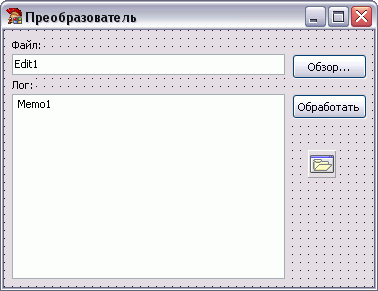
Код кнопки "Обзор…" выглядит просто:
procedure TForm1.btnBrowseClick(Sender: TObject); begin if not OpenDialog1.Execute then exit; edit1.Text := OpenDialog1.FileName; end;
Тут пока ничего необычного.
Теперь для кнопки "Обработать". Сначала нужно подключить наш юнит с классом. Это просто. Меню File – Use unit и выбираем наш юнит (он там единственный).
И пишем обработчик для кнопки:
procedure TForm1.btnWorkClick(Sender: TObject); var tt:TTextTransf; begin tt:=TTextTransf.Create(Edit1.Text); try tt.Load; //здесь мы будем вставлять код обработки tt.Save; finally tt.free; end; end;
Как видно – ничего сложного. Создали объект, загрузили текст и сохранили результат. Код обработки, который собственно выполняет основную роль, пока опущен.
Основы синтаксиса регулярных выражений
Итак, что же надо удалять? В дальнейшем повествовании я предполагаю, что вы знакомы с базовым синтаксисом HTML. Создадим в MSWord текст на несколько страниц (я экспериментировал на данной статье) и сохраним в html формате. Также сделайте резервную копию или немного модифицируqnt метод Save, чтобы он не удалял старый файл. Теперь откроем сам сохранённый файл. Как видно, MS Word очень любит вставлять тег span. Иногда по существу, иногда по факту переключения раскладки, а иногда как ему в голову придёт. Если удалить их, ни один браузер ничего не заметит (ну не совсем все, но детальнее разбираться – это уже другая история). У нас есть открывающий тег и закрывающий. С последним всё понятно – он одинаковый и можно было бы удалить и обычным поиском-заменой. В этом случае регулярное выражение будет простое - <\/span>. Только перед слешем я поставил обратный слеш. Дело в том, что слеш является спецсимволом и чтобы всё работало, символы надо "экранировать". К зарезервированным символам также относятся квадратные скобки, точка, плюс, крышка "^" и некоторые другие. Проверим наш код. Вставим на место комментария строку tt.Erase('<\/span>');
Запускаем, обрабатываем. Потом сравниваем. Должно работать.
Теперь сложнее. Надо удалить открывающий тег. Здесь могут быть различные варианты. Но для начала надо попытаться описать словами. У меня получается где-то так: "вначале угловая скобка, потом текст span потом любые символы кроме закрывающей скобки и собственно сама закрывающая скобка». На языке регулярных выражений это выглядит так:
<span[^>]*>
Конструкция [^>] означает любой символ кроме угловой закрывающей скобки. Если написать [abc], то это будет любой символ a, b или c. Конструкция вида [a-z] – какая-либо строчная буква латинского алфавита. Конструкция вида [^0-9] – все символы, кроме цифр.
Звёздочка (*) означает, что таких символов может быть 0 или больше. Если поставить +, то это будет означать, что должен быть хотя бы один символ.
Если теперь добавить ещё одну строку в наш код, то html очищается на 25%, а это уже неплохо!
Модернизация
Следующий ход – заменить конструкции вида "<p class=MsoNormal>" на просто "<p>". Наш класс не умеет делать такую замену. Но мы добавим ещё один метод. Назовём его Replace(FromText, ToText: string);
Если присмотреться, то можно заметить, что наш предыдущий метод является частным случаем этого. Erase(s) эквивалентно Replace(s,''). Поэтому добавим новый метод, скопируем туда код с метода Erase и поправим его. То-есть у нас получится так:
procedure TTextTransf.Replace(FromText, ToText: string); var r:TRegExpr; begin r:=TRegExpr.Create; try r.Expression := FromText; FText := r.Replace(FText,ToText,false); finally r.free; end; end; procedure TTextTransf.Erase(Expr: string); begin Replace(Expr,''); end;
Спросите, а в чем же прелесть? А в том, что нам не нужно менять код основного юнита! Правильно спроектированный класс скрывает функциональность внутри и при оптимизации код, который использует наш класс, не заметит изменений. Также это удобно для разделения труда. Нужно только договориться об интерфейсе классов.
Теперь код замены для нашей строки будет выглядеть просто:
tt.Replace('<p\sclass=MsoNormal>','<p>');
Здесь только одна особенность - пробел нужно записать в виде \s.
Продолжаем очистку
MS Word любит вставлять комментарии в текст, чтобы потом ему было "легче". Но браузеру эти комментарии ни к чему. Казалось бы, всё просто – берём регулярное выражение "<!--.+-->". Но попробуйте применить его - что-то много удалилось... И действительно, открыв, вы увидите, что текста удалилось много. Дело в том, что по умолчанию регулярные выражения работают в "жадном режиме". То-есть, когда под маску попадает несколько вариантов, то они пытаются захватить "побольше". Нам это только мешает, поэтому мы отключим. Это всего одна строка.
tt.Erase('<![if !vml]>'); tt.Erase('<![endif]>');
Эти строки удалят что-то не совсем мне понятное, но мешающее нормальному отображению изображений в браузере. Самое интересное, что они мешают только Internet Explorer'у. Остальным браузерам этот код - не помеха.
Посмотрим теперь на странный текст после тега html в самом верху. Уж очень много там информации. Она нужна, чтобы у html документов, созданных Word'ом отображалась немного другая иконка и именно Word вызывался при попытке редактирования. Нам это не нужно. Здесь код прост:
tt.Replace('<html[^>]*>','<html>'); tt.Erase('<meta\sname\=[^>]*>');
Украшения
Теперь добавим немного "красоты". После наших удалений осталось множество пустых строк. Удалим их. Для этого будем использовать выражение Replace('\n\s*\n',''); В классе я оформил это в виде дополнительного метода.
Выводы
После всех манипуляций мне удалось вычистить текст более чем в 2 раза. В нём, конечно, есть ещё место для ручной обработки, но в целом очень неплохо. В коде вы найдете несколько дополнительных строк для оценки производительности.
Несомненным плюсом изучения регулярных выражений будет то, что они используются во многих других языках, таких как Perl, PHP. Эта библиотека совместима с Perl'овской реализацией и поэтому литературы в Интернете предостаточно.
Автор: Вадим К
Статья добавлена: 24 ноября 2007
Следующая статья: Знакомство с SQLite »
Зарегистрируйтесь/авторизируйтесь,
чтобы оценивать статьи.
Статьи, похожие по тематике
Для вставки ссылки на данную статью на другом сайте используйте следующий HTML-код:
Ссылка для форумов (BBCode):
Быстрая вставка ссылки на статью в сообщениях на сайте:
{{a:42}} (буква a — латинская) — только адрес статьи (URL);
{{статья:42}} — полноценная HTML-ссылка на статью (текст ссылки — название статьи).
Поделитесь ссылкой в социальных сетях:
Комментарии читателей к данной статье
 Репутация: +2 |
mirt.steelwater (13 декабря 2010, 18:21): регулярные выражения - мощная вещь! спасибо, не знал, что они есть в дельфи. а нет ли в этих классах простых механизмов для отображения BBcode в компонентах типа TRichedit?
|
Оставлять комментарии к статьям могут только зарегистрированные пользователи.