
Леворекурсивный парсер
Автор: Вадим К
Введение
Иногда надо взять текст и разобрать его на составляющие, но не просто разобрать, а ещё и сделать анализ, и на основании этого получить другие данные.
Для такого преобразования обычно применяют алгоритмы, которые называются парсерами. Для определённого круга задач уже давно написаны свои готовые парсеры. Например для анализа XML. В случае простых данных можно обычно обойтись простыми функциями Pos/Copy. Но как только данные чуточку усложняются – код становится огромным и неудобным. И каждое новое добавление функциональности превращается в пытку и бессонные ночи отладки.
Простое решение
Чтобы решить эту проблему, множество ученых долго и нудно писали трактаты. Читать их – скучно, засыпаешь на первых страницах. А примеров реального кода они почему-то не приводят, даже примитивного наброска алгоритма. Только одни греческие буквы и неведомые значки.
В нескольких статьях я попробую рассказать, как написать один из простейших вариантов парсера – леворекурсивный. При правильной реализации этот парсер является одним из самых быстрых. Но он не может распарсить абсолютно всё. Например, код на языке Pascal можно распарсить с помощью чистого леворекурсивного парсера. Начиная с первых версий Delphi, парсер не такой уж и чисто леворекурсивный, однако он и не слишком усложнён. Код на языке С++ нельзя распарсить этим парсером. Для этого языка применяется парсер с возвратами. Это одна из причин, почему компилятор Делфи значительно быстрее компилятора С++. Хотя есть и ещё десяток причин :-)
Не бойтесь, если многие слова непонятны. Через какое-то время они будут восприниматься подсознательно.
Как это работает?
Суть леворекурсивного парсера проста. Символ за символом читается входной поток (например, файл или строка), и на основании прочитанного символа и некоторого множества переменных состояния делается вывод, в какое новое состояние надо перейти и как интерпретировать текущий прочитанный символ. Благодаря этому время парсинга прямо пропорционально размеру входных данных. Парсер не возвращается назад – это открывает интересные перспективы, но о них позже.
Примитивный парсер или изобретаем свой StrToInt
Скорее всего, вам известна функция StrToInt. Она позволяет из строки, которая содержит целое число, получить собственно само число, с которым может работать процессор. Строки, содержащие числа, мы ведь не можем уммножать...
Важное замечание для дотошных! Возможно, некоторые функции или конструкции покажутся вам некорректными или крайне неоптимально написанными. Не надо обвинять меня – это сделано сознательно с целью упростить код и сделать его более понятным и доходчивым. В следующих статьях некоторые функции будут переписаны, некоторые удалены, а назначение некоторых странностей станет понятным. С другой стороны, я не запрещаю вам эксперементировать и пытаться написать более «отимизированно».
Для начала сделаем примитивную форму для тестов, которую мы будем использовать в большинстве последующих примеров. Для кнопки «Расчёт!» напишем такой код:
procedure TForm1.Button1Click(Sender:TObject); begin Edit2.Text := FloatToStr(Parser(Edit1.Text)); end;
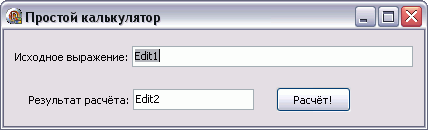
Функция Parser – это наша функция, которая получает строку и отдаёт число. Правда мы тут же его преобразовываем снова в строку. Но это пока. И пусть не смущает то, что я говорил о IntToStr, а использую дробные числа. Всё станет на свои места позже.
Заготовка парсера
Привожу код самого парсера с комментариями. (Полный проект – в папке Demo1).
unit MyParser; interface uses SysUtils; function Parser(s: string): double; implementation var InpStr: string; //Копия входной строки InpPos: integer;//Номер текущего символа CurrChar: char; //Копия текущего символа //Процедура берёт следующий символ из строки procedure GetNextChar; begin if InpPos < length(InpStr) then begin Inc(InpPos); CurrChar := InpStr[InpPos]; end else CurrChar := #0; end; //Функция чтения числа function GetNumber:Double; begin result := 0; while CurrChar in ['0'..'9'] do begin result := result * 10 + ord(CurrChar) - ord('0'); GetNextChar; end; end; //Парсер :) function Parse: double; begin result := GetNumber; if CurrChar <> #0 then raise Exception.create('В конце строки неизвестные символы!'); end; //Иницализация и запуск парсера function Parser(s: string): double; begin InpStr := s; InpPos := 0; GetNextChar; Result := Parse; end; end.
Этот код будет основой для всех последующих парсеров. Давайте кратко разберём фунции.
Функция Parser. Эта функция вначале инициализирует внутренние переменные (первые две строки), читает первый символ (он автоматически помещается в глобальную переменную CurrChar) и последней строкой вызывает функцию, которая, собственно, и делает парсинг.
Функция Parse также не делает ничего сложного. Она читает число из потока (об этом ниже). После того, как она прочитала число, там больше ничего не должно быть, это ведь функция преобразования строки в число. Если там что-то обнаружено – генерируем исключение.
Продвигаемся дальше вглубь. Функция GetNumber. Перед её анализом, давайте подумаем, что такое обычное целое число. Это просто последовательность цифр. А теперь смотрим на функцию. Она работает просто. Проверяет текущий символ: если он - цифра, то сохранённый результат умножает на 10 и добавляет значение цифры. Перевод из символа цифры в число я делаю конструкцией Ord(CurrChar) - Ord('0'). Это очень старый, но очень быстрый способ. Можно было, конечно, использовать функцию StrToInt, но смысл? :-) После обработки текущего символа переходим к новому (процедура GetNextChar).
Попробуйте пробежать глазами всю эту цепочку снова, и понять как она работает. Весь дальнейший код будет основан на этом же принципе.
Заметье, что функция GetNumber читает до тех пор, пока в входном потоке есть цифры. Если их там нет – она выходит. Её абсолютно не волнует, что там дальше. Это забота другого кода.
И на последок рассмотрим процедуру GetNextChar. Она работает тоже крайне примитивно. Пока в строке есть ещё символы – она увеличивает счётчик и присваевает CurrChar текущий символ. Если символов больше нет – возвращает нулевой символ.
А теперь попробуйте ответить на простой вопрос. Знает ли функция Parse или GetNumber о том, откуда берутся следующие символы? Нет! Им этого и не нужно знать. Только процедура GetNextChar знает, как их получить, ну и функция Parser умеет подготовить данные. Это позволяет с лёгкостью заметить источник данных без переделки всего кода. Например, захотели мы читать данные из файла. Нам надо переделать только эти две функции. А как именно – это будет первым домашним заданием.
Первое улучшение
Парсер у нас хороший, но если ввести не просто число, а добавить пару пробелов в начало и в конец, то он уже ругается. Непорядок! Надо исправить. И для этого нам нужно всего пару строк (этот пример можно найти в папке Demo2).
Первое – напишем простую процедуру:
procedure SkipSpace; begin while CurrChar in [' ', #9] do GetNextChar; end;
Эта процедура читает из входного потока символы, и, пока они пробелы или символы табуляции, пропускает их. Если вам захочется, что бы символ подчёркивания тоже был пробельным символом – просто добавьте его в этот список.
Теперь осталось добавить вызов. Пока я сделал так:
//Функция чтения числа function GetNumber:Double; begin result := 0; SkipSpace; while CurrChar in ['0'..'9'] do begin result := result * 10 + ord(CurrChar) - ord('0'); GetNextChar; end; SkipSpace; end;
Запустите программу и попробуйте вводить различные строки. Она с лёгкостью переваривает их!
Простой калькулятор
Я надеюсь, вы заметили название формы – простой калькулятор. И мы сейчас его сделаем! Правда, он будет уметь только складывать и вычитать числа. Но зато он будет уметь это делать!
Итак, научим наш калькулятор понимать выражения вида «1 + 23 + 456 - 789» Заметьте, с пробелами, и со знаками плюс и минус. Для начала посмотрим на эту строку. Что же мы видим? Вначале надо прочитать число, потом в цикле читать знак и ещё одно число, и производить операцию.
Посмотрите на то, что написано ниже:
//Парсер :) function Parse: double; begin Result := GetNumber; repeat case CurrChar of #0: exit; //Достигли конца строки '+': //Нужно сложить begin GetNextChar; Result := Result + GetNumber; end; '-': //Нужно вычесть begin GetNextChar; Result := Result - GetNumber; end; else //Какой-то неизвестный символ. raise Exception.CreateFmt( 'Я пока умею складывать и вычитать!'#13#10+ ' В строке обнаружен символ %s в позиции %d', [CurrChar, InpPos]); end; until False; end;
Как видно – ничего больше, чем я сказал, когда давал определение.
Домашнее задание
Если не работать над собой, а пользоваться только чужим кодом, долго не протянешь. Поэтому я предлагаю небольшие задания. Одно уже было озвучено. Вот ещё несколько.
Научите парсер уммножать и делить. Пока что без учёта старшинства операций. Можно и степень ввести (символ ^).
Научите парсер понимать выражение вида PI * 2, где PI – это 3.14, то есть, число пи. Хотя это и кажется сложным заданием, на самом деле оно очень простое.
Найдите и попробуйте исправить как минимум две ошибки в реализации функции GetNumber.
А дальше?
В следующей части мы научим наш парсер работать с дробными числами и с шестнадцатеричными.
Примеры к статье (исходники 3 демо-проектов) »
Автор: Вадим К
Статья добавлена: 8 марта 2009
Следующая статья: Процедуры для работы с динамическими переменными »
Зарегистрируйтесь/авторизируйтесь,
чтобы оценивать статьи.
Статьи, похожие по тематике
Для вставки ссылки на данную статью на другом сайте используйте следующий HTML-код:
Ссылка для форумов (BBCode):
Быстрая вставка ссылки на статью в сообщениях на сайте:
{{a:52}} (буква a — латинская) — только адрес статьи (URL);
{{статья:52}} — полноценная HTML-ссылка на статью (текст ссылки — название статьи).
Поделитесь ссылкой в социальных сетях:
Комментарии читателей к данной статье
 Репутация: +1 |
igoriy (29 октября 2009, 08:33): Очень интересно,спасибо.Только вот написано про продолжение , а где оно?
|
 Репутация: нет |
gyhy (5 апреля 2009, 01:17): просто и оригинально
|
Оставлять комментарии к статьям могут только зарегистрированные пользователи.
